NFTs and Oracles Beyond the Hype

Building an End-to-End Trusted Ecosystem for Data
Building an End-to-End Trusted Ecosystem for Data
What are NFTs?
Non-fungible tokens (NFTs) have brought in a new era of digital collectibles, hitting a trade volume of $25 billion in 2021, according to Reuters, adding to the list of physical items such as baseball cards, art, antiques, and plush toys, whose value mainly stems from the interest of collectors. From being heralded as a new form of ownership, to being branded as completely outlandish, there are a wide variety of opinions about NFTs.
Just like blockchain is often conflated with Bitcoin, its most well-known implementation, the term NFT is used interchangeably with specific examples of digital collectibles, some being quite unconventional, such as NFTs of tweets. The perception of blockchain and NFTs is often tied to the perception of such newsworthy instances, limiting their perceived potential. However, drawing a distinction between sensational implementations of NFTs and the underlying technology, and adapting the methodology to fuse identity and data, can bring trust in the data value chain and enable other use cases.
Tokenization of assets
Tokenization of assets on the blockchain enables the digital encapsulation of something of value. Tokenization is thus a prerequisite for trading assets on the blockchain. Assets on the blockchain mainly fall into one of two categories depending on how value is held, as seen in Figure 1. Non-fungible assets hold value in large part due to their unique identity. Non-fungible assets are not readily liquid, cannot be divided into smaller parts, and are not interchangeable.
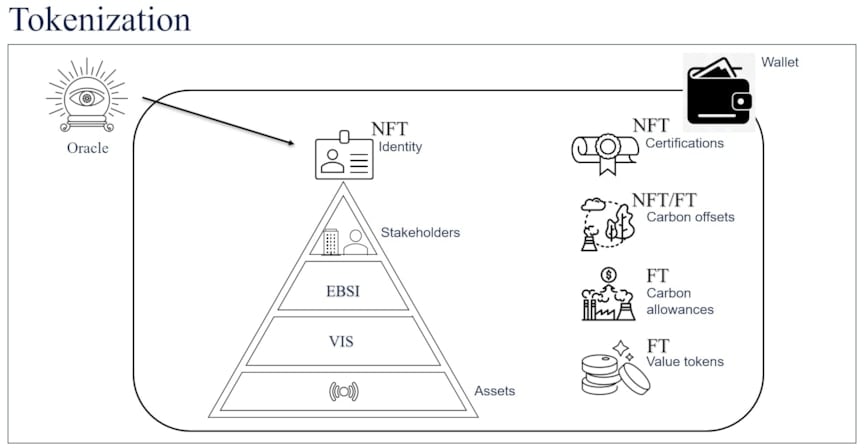
Figure 1: Types of Blockchain Tokens
Fungible assets hold value and are so called due to established fungibility or equivalence between tokens. Fungible tokens can be thought of as fiat currency: a $100 note has the same value as ten $10 notes, and as two $50 notes, and so on. Thus, suppose a friend borrows a $100 note, putting preferences aside, any of the alternatives could be equivalent for paying back. However, if that particular $100 note is rare for some reason and has value not due to its status as legal tender, but due to another property, that could be encapsulated as an NFT. Taking another example, a non-fungible token can be thought of as a car. If a friend borrows a car, then a different car or two parts of a car would not be considered as reasonable equivalents. The two types of tokens thus intuitively lend themselves to encapsulate assets of different types.
Tokenized identity
Identity on the blockchain, or lack thereof, has been the cause for controversy before. The infamous Silk Road marketplace used the anonymity afforded by Bitcoin to host the exchange of illegal services and commodities such as drugs on the dark web. The aftermath has shown two facts: one is the need for identity on a blockchain system; the other is that blockchains are not truly anonymous anyway. Further, establishing a standardized identity framework is necessary to bring public trust into blockchain-based solutions beyond the proof-of-concept stage.
Identity is the basis for trust and legally mandated in business applications through know-your-customer and anti-money-laundering regulations. Both consumer and business applications rely on being able to uniquely identify a person. A person needs access to their identity many times during the day, from unlocking their phone and being allowed to drive their car, to accessing their workplace or bank accounts and signing agreements. Identity thus has many dimensions beyond what we intuitively think of as our identity. Identity carried by a person can be a voter card, a social security card, or a driving licence, each saying who you are and giving you access or a right to do something. A person’s identity is encapsulated in identification cards issued by different authorities; thus, identity has many dimensions depending on the context. All these identities are components of your whole identity and are valid only for the identity subject. Identities are unique, indivisible, and non-interchangeable.
In the physical world, these identities are issued by authorities that are known and trusted. When issuing an identity, the issuer must first confirm your identity based on other documentation. For instance, in order to acquire a driving licence, one must present another proof of identity. There is often a root of your identity, such as your national identity number, which is attached to every identity you have. Often, you acquire other identities based on one that you already have, which makes the root a very important identity to secure. Finally, to safely carry around all these identities, you store them in a wallet that you keep safe.
Identity online, i.e. digital identity, is as important as it is in the physical world. Identity is not only a ticket to trade for most blockchain applications, but can also enable applications in its own right, driven by digitalization of our lives and businesses. While not intuitive, identity is an asset of considerable value, and as services move online, identity must follow suit.
The EU Commission’s European Blockchain Services Infrastructure (EBSI) initiative further shows the importance and regulatory interest in blockchain-based identities. The EBSI has the ambition to give a digital identity to each natural person and legal entity in the EU. The most researched use cases in the EBSI are educational credentials and asylum applications, but such a digital identity has far-reaching applications. Further, identity is not restricted to persons and organizations who are stakeholders in a value chain, but also extends to assets. The DNV sensor naming rule Vessel Information Structure (VIS), which is based on the ISO 19848 standard, provides a hierarchical naming scheme for sensors and components based on function.
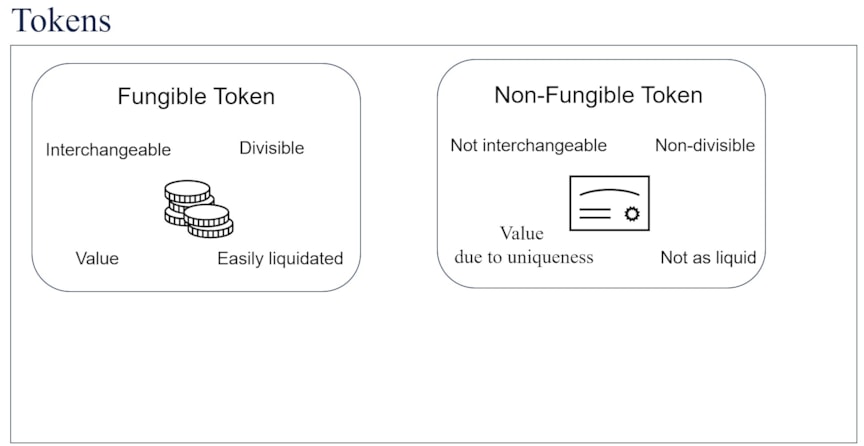
Figure 2: Structured identity and blockchain wallet
A hierarchical and integrated identity will bridge the VIS identity of assets and the EBSI identity of stakeholders, thus ensuring the traceability of data at the granularity level of sensors. This identity will be used to sign the data streams and enable a trusted data pipeline, as a part of a larger ecosystem of data. An identity, if issued as an NFT, can allow a person to claim and prove their identity with cryptographic guarantees. This root identity structure, as seen in Figure 2, can then underpin the ownership of tokens of value, such as certificates of compliance or even additional identities. For an enterprise, these can either be fungible tokens of value or non-fungible tokens, such as carbon allowances, carbon offsets (which could also include fungible components), and certifications. As in the physical world, these identities and coin tokens can be securely stored in a wallet.
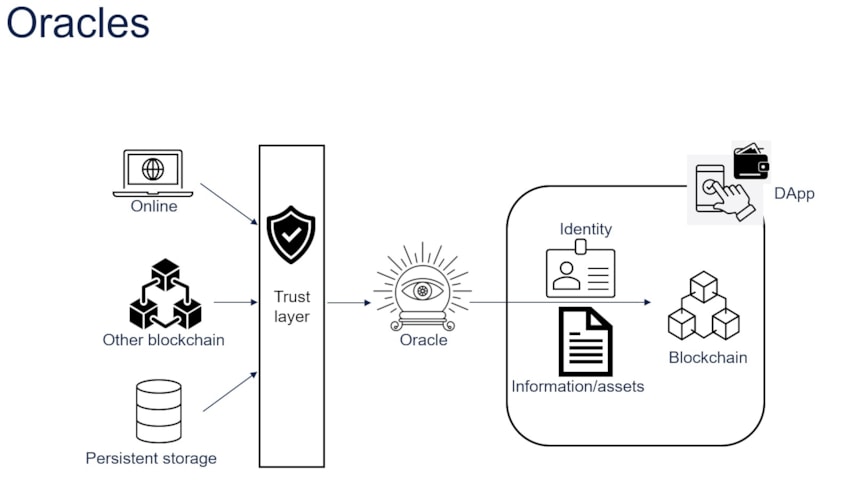
Figure 3: Translating physical-world safeguards and bridging on- and off-chain storage
The trusted identity issuers in the physical world translate into oracles in blockchain parlance. A blockchain system is closed to the outside world and needs oracles – trusted data sources bringing in data and identity from the outside world – as seen in Figure 3. For instance, if a smart contract encodes a bet between two individuals based on the outcome of a race, this information must be delivered into the smart contract. Oracles in a blockchain ecosystem can attest to the veracity of data and identities and allow the ecosystem to push advanced computations off chain. However, blockchain oracle mechanisms using a centralized entity to inject data into a smart contract create a single point of failure, defeating the entire purpose of a decentralized blockchain application and raising the question of who holds the oracle accountable. This apparent chicken-and-egg scenario can be resolved by increasing the need for evidence from the oracle. In other words, the oracle must be able to show their work on demand. Additionally, the oracle must not be able to change the source data after the fact. Finally, there must be a way to present proof of non-tampering of data in a way that can be easily examined by a stakeholder.
Standardized data collection and tamperproofing
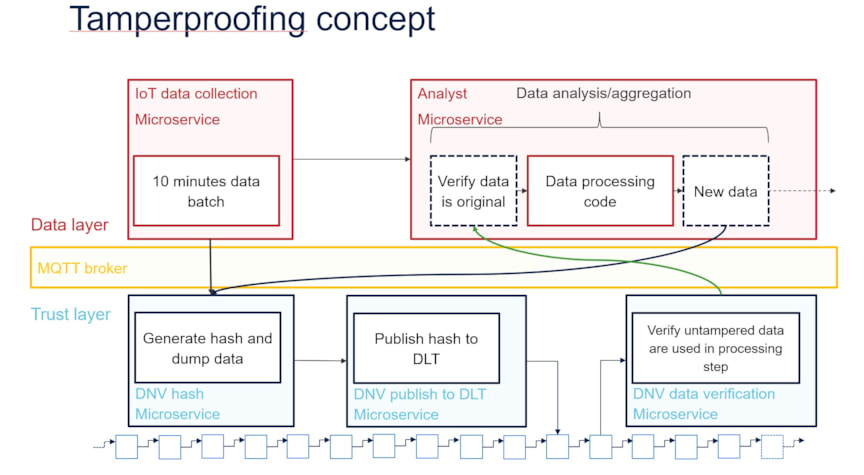
Figure 4: VidaMeco architecture
Today, data streams generated on board vessels are transmitted to data consumers on shore by ad hoc and disparate means and thus require keeping track of several different and non-integrated data pipelines. Such a complex system is not easily scalable, as adding a new data resource or supporting multiple services using several separately collected data points becomes challenging. Another challenge is ensuring data integrity between processes in resource-constrained environments where data transfers are not immediate. The integrity of the data is vital, as the possibility of undetected tampering could severely undermine trust in the data and services relying on it.
Our blockchain use case, developed and demonstrated in the VidaMeco research project, comprises an integrated hardware and software solution for standardized data collection and tamperproofing using microservices and blockchain. This work was partially funded by the Research Council of Norway. Figure 4 shows the architecture of the VidaMeco solution. Microservices are developed to collect edge data batches. These batches are hashed, and the hash is published to the blockchain. Later, the data consumer can use our distributed application (DApp) to access a microservice for verification of data integrity based on the published hash. A DApp is an application that combines traditional database backend with a blockchain backend. Using this methodology as a base for oracle inputs will essentially allow the oracles to substantiate their decisions based on trusted data, thereby increasing trust, reducing centralization, and ensuring traceability.
VidaMeco can be used to enable standardization and data integrity for a variety of use cases in shipping as well as other industries, driving digitalization and making the data value chain robust, verifiable, and scalable.
Architecture of ecosystem
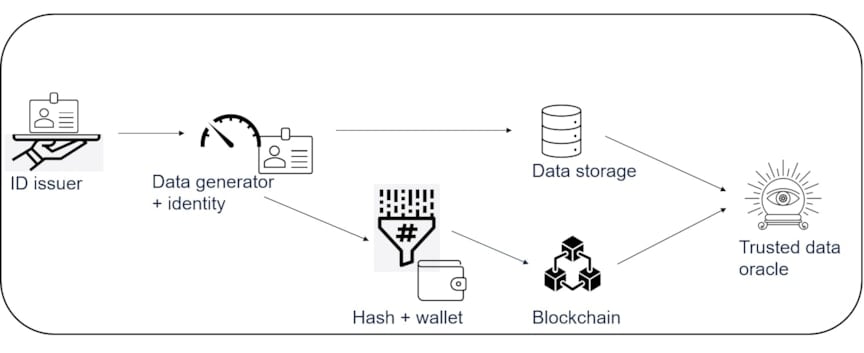
Figure 5: Architecture of ecosystem
Putting together the building blocks of NFTs, oracles, tamperproofing, tokenized identity, and assets, we now describe the ecosystem architecture for improving trust in data. Figure 5 outlines the data flow between major components of this architecture. First, the identity issuer creates and issues an identity NFT to each asset and stakeholder in the business network. This identity is fused together with the data streams to ensure that all data has provenance. The data is hashed in batches, and using the blockchain identity in the wallet, the hash is stored on the blockchain. The source data goes its separate way to be stored in an off-chain storage solution controlled by the data owners. The data stored in the off-chain solution is secured from read access using access control mechanisms based on the identity structure as well as cybersecurity methodologies that are outside the scope of this article. The data is further protected from tampering by the hash stored on the blockchain. The trusted oracle combines the sources of data and trust and supports the execution of hybrid and multichain smart contracts spanning the entire value chain.
Example use case 1: Digital twins
Investment in digital twins is on the rise with global digital twin market expected to reach over $100 billion by 2030, as per multiple market studies. Digital twins have been used in projects involving large objects such as buildings and bridges, mechanically complex constructions such as wind turbines and jet engines, and in automotive manufacturing. When successful, digital twin modelling can increase operational efficiency and lifetime, improve asset performance, and help achieve compliance with regulations. These benefits can directly translate into the bottom line.
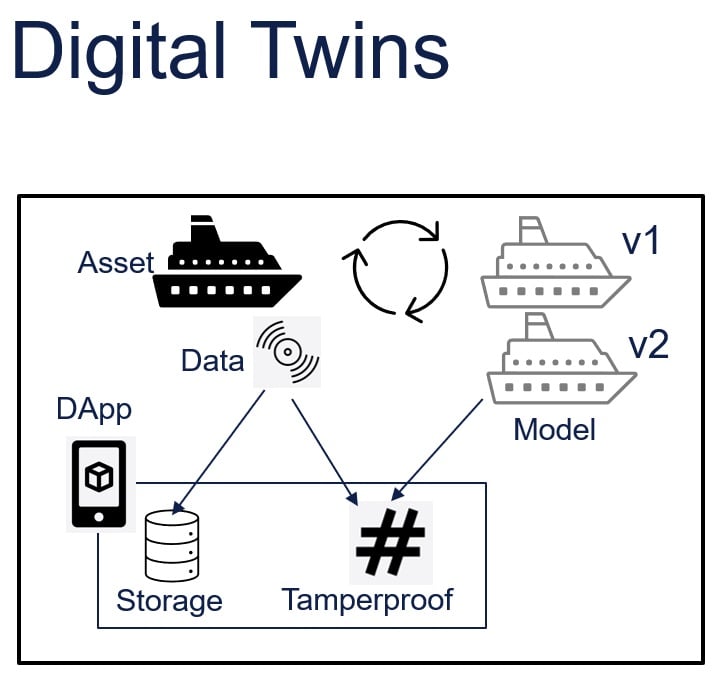
Figure 6: Integration with Digital Twins
A digital twin is a digital model of an asset or process, contextualized by a digital version of its environment. The object or process being studied, for instance a wind turbine, is equipped with sensors related to vital operations, which produce data about different aspects of the physical object’s performance, such as temperature, energy output, weather conditions, etc. This information is applied to the digital copy, which simulates the system states and generates insights that are shared with the physical copy. This two-way flow of information involves data integration from multiple-source systems, integration of OT (Operational Technology) and IT systems, and thus requires good data structure, governance, and quality.
However, studies, such as the one by BCG [BCG2019], show that investments in digital twins often fail to generate value. The issues highlighted include:
A successful solution must thus solve the issue on two fronts – trust and integration – and must build an end-to-end solution focused on value for stakeholders.
To improve integration of data from many sources and stakeholders into work processes, the data pipeline must have a foundation of a robust identity structure to easily establish data provenance. The structure should include a digital signature of each user and a fingerprint of each asset and model version responsible for data and outcomes. The chain of versioning must be kept up to date in order to connect insight with the code version that produced it. Further, digital twins are highly reliant on sensor data quality and integrity, so to have trust in the model, the data pipeline must be secured against unauthorized edits. Hashing the data in batches and publishing the hash to the blockchain against the identity of the data originator, whether asset or stakeholder, will tamperproof the data at the start of the value chain. Additionally, the digital twin version information must be hashed and published to the blockchain every time a version is updated. This will ensure that data and code are both tamperproofed.
A more traceable data pipeline – as seen in Figure 6, integrated into an end-to-end ecosystem for data ingesting, structuring, and reporting – is essential to extract value from digital twins.
Example use case 2: MRV compliance reporting
Regulatory actors such as the IMO and EU have pushed for digitalization and traceability of emissions through their Facilitation Convention and inclusion of shipping in the Emissions Trading System (ETS), respectively. With the introduction of market-based measures comes the incentive to adjust emissions reported in order to reduce costs. For instance, in 2009, Europol found that carbon credit fraud in the ETS system cost €5 billion in lost tax revenue. More recently, in 2023, an instance of a multimillion-euro ETS fraud was found in Bulgaria. According to Reuters, ETS had a market value of €751 billion in 2023; and, according to Hellenic Shipping News, the projections for ETS costs for shipping alone are €3.1 billion (2024), €5.7 billion (2025) and €8.4 billion (2026), factoring in the three-year phase in. The estimated daily ETS cost of €10k for a container ship would translate to north of a million per annum per vessel, assuming more than 100 sailing days. With the current acceptable margin for error in Monitoring Reporting and Verification (MRV) (5%), which forms the basis of ETS calculations, this would mean a difference of €50k per vessel per year.
As regulation is now moving towards demanding more granularity and transparency in emissions reporting, aggregated annualized reporting may not be sufficient in the near future.
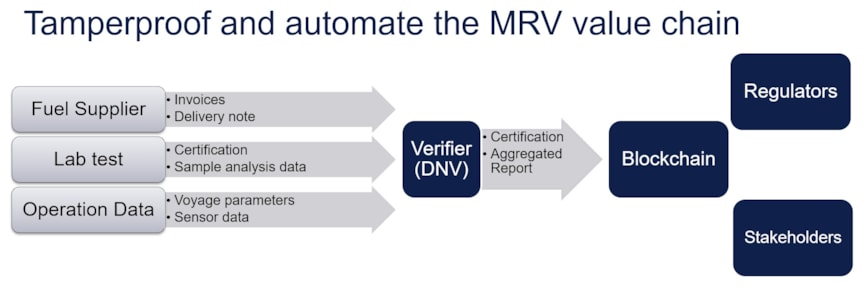
Figure 7: MRV value chain
The MRV reporting value chain, as seen in Figure 7, is complex, with many stakeholders, each with their own systems of record and data. Currently, annual emissions calculations are not based on sensor measurements on board a ship; they are estimated based on the fuel consumption data and operational data reported by the ship in daily reports called noon reports. The fuel consumption reported in the noon reports is substantiated by invoices on fuel sale and by sample studies done in laboratories on fuel samples from a batch. To comply with reporting requirements, all this data must be submitted to an accredited verifier, like DNV, for consistency check and verification before being submitted to the EU Commission.
The documents are delivered to the verifier by email from each stakeholder in an unstructured fashion, as seen on the left-hand side of Figure 8. Sorting and structuring these documents, requesting missing documents, as well as checking for class certifications and validations, is an extensive paper-based and document-heavy process. As regulation continues to evolve, this unstructured data makes it more challenging to keep up. Data that is granular, tamperproofed, and structured by identity will ease combining data sets in different ways, reducing rework and producing evidence-based reports. A study by BCG estimated that digitalization can reduce OPEX in shipping by 15%, which is significant in such a price-sensitive sector.
The right-hand side of Figure 8 shows our proposed solution. Here, a fuel supplier issues a bunkering invoice and tamperproofs it using our solution so that the hash of the bunkering invoice is published on the blockchain against the identity of the fuel supplier. This hash is meaningless without the source data and cannot be used to get any information about the source data, including size of data. Similarly, the laboratory produces and tamperproofs their reports. The ship starts the voyage and collects and hashes data in 10-minute batches using the hierarchical identity and publishes the hashes to blockchain. The source data for all three stakeholders is stored in an off-chain repository. Later, when the MRV verifier is given access to this off-chain database, they are able to retrieve the stored data, structured by stakeholder and sensor identity, and verify its integrity against the hash stored on the blockchain.
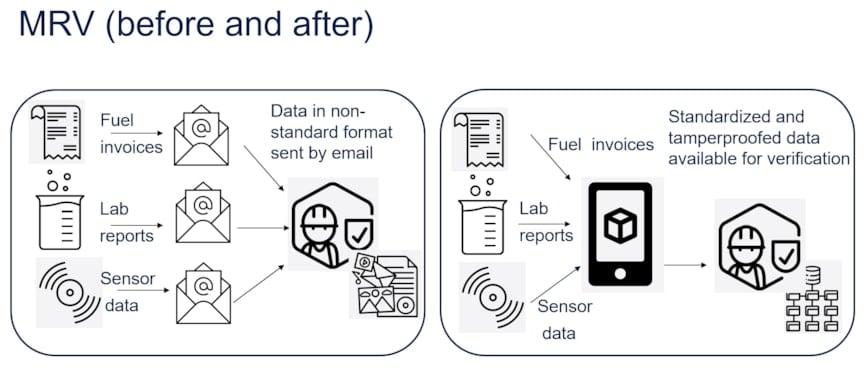
Figure 8: MRV data pipeline before (left) and after (right) integration of the solution.
Standardized data collection and edge data integrity underpinned by identity can improve granularity and accuracy and make it harder to falsify data, so that the EU and IMO regulations will have greater effect and contribute to a fair distribution of costs.
Concluding remarks
As industries that are traditionally document-heavy continue to digitalize, there is a push to replicate and encapsulate physical-world safeguards and trust models in an increasingly complex landscape. Development in sensor technology, as well as the ubiquity of sensors in industrial applications, means that organizations have a huge amount of data at their disposal. This data can generate valuable insights for operational improvement, decision support, and simplified compliance reporting, but is underutilized in the absence of standardized data structures and easily verified data provenance. Fusing identity and data using NFTs and oracles can be the foundation for building a variety of use cases where trust in data is essential.
References:
[BCG2019] Creating Value with Digital Twins in Oil and Gas, BCG 2019 (link)
For further reading, please see the following papers that were produced as part of the VidaMeco project:
K. E. Knutsen, Q. Liang, N. Karandikar, I. H. B. Ibrahim, X. G. T. Tong and J. J. H. Tam, ‘Containerized immutable maritime data sharing utilizing Distributed Ledger Technologies’, Journal of Physics: Conference Series, Volume 2311, The International Maritime and Port Technology and Development Conference (MTEC) & The 4th International Conference on Maritime Autonomous Surface Ships (ICMASS), 2022. https://iopscience.iop.org/article/10.1088/1742-6596/2311/1/012006.
N. Karandikar, K. E. Knutsen, S. Wang and G. Løvoll, ‘Federated Learning on Tamperproof Data for PHM on Marine Vessels Using a Docker Based Infrastructure’, Annual Conference of the PHM Society, 14(1). https://doi.org/10.36001/phmconf.2022.v14i1.3149. 2022.
S. Wang, N. Karandikar, K. E. Knutsen, X. G. T. Tong, T. Edseth and Z. Z. Xu, ‘Enhancing Maritime Data Standardization and Integrity using Docker and Blockchain’, IEEE/ACM 45th International Conference on Software Engineering: Companion Proceedings (ICSE), pp. 370-374, https://ieeexplore.ieee.org/document/10172812. 2023.